This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Reduce Storage Costs – by getting rid of your ROT (redundant, obsolete or trivial) data BEFORE migration, plus the potential cost saving of infrastructure maintenance over license fees. Step 1: Improve Content Metadata. High-quality metadata is essential to improving search results. Step 2: Classify Your Data.
Make the most of metadata by utilizing systems that help automate how metadata is applied while retaining unstructured data in place. Put more intelligence into governance either by auto-tagging and categorizing content to kick off a retention workflow or by proactively managing the archival of business content and disposal of ROT.
Process Dependencies: Work processes, both manual and automated, may rely on how a system works, what its reports contain, how its metadata is structured, and more. Missing Metadata: This is often the case because new fields were added; in many instances, these new fields are also mandatory. This is also known as metadata enrichment.
There is no SharePoint fairy that assesses all your information, uploads just the valuable stuff to SharePoint, applies appropriate access controls, and fills in the metadata. It includes leveraging SharePoint's capabilities to streamline and automate common tasks like applying metadata, retention management, and basic workflows.
Redundant, obsolete, and trivial (ROT) information likely dominates your content stores. We collect data from organizations every day to understand why information governance problems exist, and there are generally five reason your files are ROT(ting). Five Reasons Your Files are ROT(ting) 1. Does it drive workflow?
Metadata Capture and Remediation: Again, users are the problem with metadata more than the solution. We can automate metadata capture at the time information is captured; we can also correct missing or incorrect metadata, at speed and at scale.
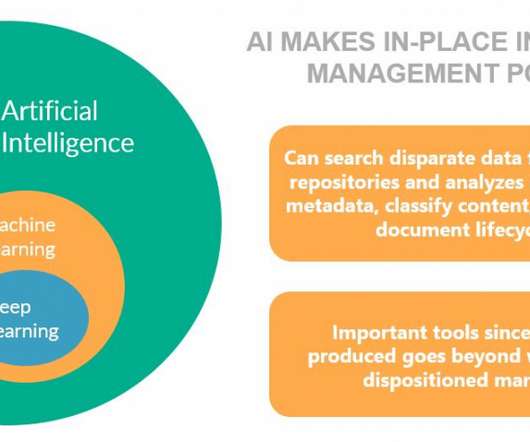
Organizations must embrace AI and ML tools to take the friction out of the process of manually classifying incoming information and assigning relevant metadata. AI and ML capabilities need to be viewed in two contexts by user organizations. The result: an unmitigated content mess!
Well the good news is that Twitter has a very comprehensive API that allows you to extract everything about a tweet in JSON format including the text and plenty of metadata – everything you could possibly need for preservation. However, the challenge is that a tweet contains other information alongside the text and metadata.
Apply ROT data remediation to purge unused or obsolete files Establish Clear Governance Strong governance structures ensure consistent application of retention policies: 1. Schedule ROT Data Remediation tasks to keep systems clutter-free 3. Employ varying retention periods and storage levels to prevent unnecessary overhead.
File and content analysis solutions provide capabilities to analyze your information and either automatically or manually enrich and classify it by assigning taxonomy and metadata. You can scan your information for PII, PHI, PCI, custom regular expressions, named entities and so on, to automate metadata creation.
We say 80% of a company’s content is ROT – redundant, obsolete and trivial – and that keeping it is causing real challenges including storage costs and the risk of theft (both intentionally and accidentally). You can see the label when you look at the metadata for an individual file. So you get it. We get it.
ROT (redundant, outdated, trivial): A term that’s become common in information-related discussions, it has been added this year simply as ROT. The term may become “redundant, outdated, trivial (ROT)” to help those who are newer to the profession who may benefit from the descriptive term.
Digital disasters of systems are increasingly common due to a number of factors including human error, computer job error, natural and manmade disasters, cybercrime, bit rot, and file format obsolescence. Here are examples of how disk rot, a natural disaster, and data breaches can cause monumental losses. Are you protected?
By connecting to places where information lives, indexing and classifying content and metadata, illuminating dark data, and targeting ROT for removal, organizations can reap the benefits of identifying their most valuable information assets.
This is often a great time to clean up information ROT (redundant, obsolete, trivial). Inventory source content and metadata. Here are some important considerations: If there are any information architecture changes required, the migration will be more complex than a simple "lift and shift" of content. Develop test plan.
To do that, they need to get buy-in (and funding) from executives to establish programs and processes that will: Clean out the information no longer needed, including ROT and information past its retention period or value to the business.
Metadata enhancement: Adding new tags based on extracted entities and other content elements. Identify – Automatically find the ROT and sensitive information. It could be location-based, context-based, information-type based. Manage Dark Content. Classify – Based on those properties, automatically classify the content.
Demonstration and proof of concept In the screenshot below, the user of the Chrome browser has visited a (malicious) website and you can see the result is a forced download leading to the side effect of a crash in a process unrelated to the web browser: “We’re sorry, it looks like the Tracker Metadata Extractor crashed.” This is super big.
When tagging and auto-classifying content, the AI engine can extract metadata to provide context to unstructured content. Investopedia defines NFTs as “cryptographic assets on blockchain with unique identification codes and metadata that distinguish them from each other. Blockchain, Provenance, and Authentic Information.
Below is our second in a series of blog posts written by Carla Mulley, Vice President of Marketing at Concept Searching. Concept Searching and Gimmal are working together to offer more intelligent records management capabilities to organizations of all sizes.
This phase would include the following steps: Take Inventory of the Source System: This means identifying the information in the system, its metadata, how it is categorized and classified, any relevant business rules or workflows, security settings, etc. Or is much of it redundant, outdated or obsolete, or trivial (ROT)?
Separate the good information from the ROT. After you’ve received input from key stakeholders, you can start to define content categories (or content types) and associated metadata. A good example here is identifying and dealing with ROT. Respond quicker to requests for information. Assign cost-effective storage tiers.
By implementing an intelligent metadata layer between a common mobile user interface and disparate repositories, electric utilities create a repository-neutral tier that enables seamless, interprise access. Connecting and consolidating the content from their disparate repositories is a major concern for users.
Auto-classification can leverage AI using RPA and ML / MT to analyze the digital content and categorize it, including redundant, obsolete, and temporary (ROT) [4] content. Much of the content will never be accessed, yet the cost to manage ROT content will continue to increase. Figure 1: Auto-classification and AI.
We organize all of the trending information in your field so you don't have to. Join 55,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content