This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
“By applying a methodical datascience approach to analyzing our dataset, we were able to build a classifier that effectively finds bots at a large scale.” Practical datascience techniques can be used to create a classifier that could help researchers in finding automated Twitter accounts.
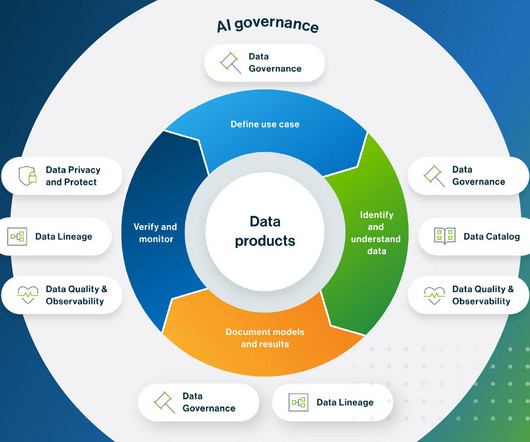
So when DataScience teams think about AI governance, they think model management. Model management, an element of MLOps, ensures that datascience best practices are followed when building and maintaining an AI model throughout its lifecycle. Notice that “AI use case” is the subject, not the AI model.
What is metadata, and why is it so important when archiving electronic records? Metadata is descriptive information (data) about stuff. Without all of this metadata you would be holding a blank box that may or may not be free but definitely is a mystery. This is such a pervasive thing that it can be hard to describe.
This includes capturing of the metadata, tracking provenance and documenting the model lifecycle. It drives a complete governance solution without the excessive costs of switching from your current datascience platform. Lifecycle Governance: Monitor, catalog and govern AI models from anywhere and throughout the AI lifecycle.
I interviewed him this November to discuss his thoughts on the evolution of metadata, content classification, AI, and how companies are using the new pillars of datascience to break down their silos, help customers get lean and discover the hidden values in their big data sets.
Typically, on their own, data warehouses can be restricted by high storage costs that limit AI and ML model collaboration and deployments, while data lakes can result in low-performing datascience workloads. New insights and relationships are found in this combination. All of this supports the use of AI.
Gartner defines a data fabric as “a design concept that serves as an integrated layer of data and connecting processes. The data fabric architectural approach can simplify data access in an organization and facilitate self-service data consumption at scale.
It drives an AI governance solution without the excessive costs of switching from your current datascience platform. The resulting automation drives scalability and accountability by capturing model development time and metadata, offering post-deployment model monitoring, and allowing for customized workflows.
Collibra Adaptive Data and Analytics Governance helps create a culture of trusted data that fuels better decision-making by: Bringing metadata into one central location via native integrations and APIs to important data sources, business applications, datascience and BI tools so that data is available and easily accessible across your organization.
IBM Cloud Pak for Data Express solutions offer clients a simple on ramp to start realizing the business value of a modern architecture. Data governance. The data governance capability of a data fabric focuses on the collection, management and automation of an organization’s data. Datascience and MLOps.
These new technologies and approaches, along with the desire to reduce data duplication and complex ETL pipelines, have resulted in a new architectural data platform approach known as the data lakehouse – offering the flexibility of a data lake with the performance and structure of a data warehouse.
I interviewed him this November to discuss his thoughts on the evolution of metadata, content classification, AI, and how companies are using the new pillars of datascience to break down their silos, help customers get lean and discover the hidden values in their big data sets.
Lock and unlock Business Workspaces A new event bot automatically locks and unlocks Business Workspaces based on predefined metadata conditions, ensuring data integrity during approval processes. Additional metadata can also now be passed to DocuSign. and later, ensuring faster access to content.
Automated, integrated datascience tools help build, deploy, and monitor AI models. Often data scientists aren’t thrilled with the prospect of generating all the documentation necessary to meet ethical and regulatory standards. It’s not just about granting proper access to datascience teams.
Through workload optimization an organization can reduce data warehouse costs by up to 50 percent by augmenting with this solution. [1] 1] Users can access data through a single point of entry, with a shared metadata layer across clouds and on-premises environments.
With Collibra Data Intelligence Cloud, researchers and datascience teams can easily collaborate with data and enable explainable AI resulting in greater transparency and auditability across data sets and models.
GCP offers a range of tools to support these processes, including Dataflow for streaming data, Dataproc for Hadoop/Spark stacks, Data Fusion (for integrating data from multiple sources) and Dataprep (for data wrangling).
Several items quickly raised to the top as table stakes: Resilient and scalable storage that could satisfy the demand of an ever-increasing data scale. Open data formats that kept the data accessible by all but optimized for high performance and with a well-defined structure. Comprehensive data security and data governance (i.e.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. An AI governance toolkit lets you direct, manage and monitor AI activities without the expense of switching your datascience platform, even for models developed using third-party tools.
What is metadata, and why is it so important when archiving electronic records? Metadata is descriptive information (data) about stuff. Without all of this metadata you would be holding a blank box that may or may not be free but definitely is a mystery. This is such a pervasive thing that it can be hard to describe.
By supporting open-source frameworks and tools for code-based, automated and visual datascience capabilities — all in a secure, trusted studio environment — we’re already seeing excitement from companies ready to use both foundation models and machine learning to accomplish key tasks.
It should be able to bring metadata from all of your important data sources, no matter where they are located, into a central location so you can get full visibility of your data. It should provide all of the data catalog and governance capabilities you need to manage and govern your data.
Business-specific metadata is the foundat ion of effective search, workflow, and other value-creation activities in content-centric business applications. Some services are easy to deploy and provide generic metadata not based on a businesses specific content.
Congress first proved how much the government could benefit from using data evidence to create policies and inform programs when the Foundations for Evidence-Based Policymaking Act came into effect in January 2019.
Collibra Adaptive Data and Analytics Governance helps create a culture of trusted data that fuels better decision-making by: Bringing metadata into one central location via native integrations and APIs to important data sources, business applications, datascience and BI tools so that data is available and easily accessible across your organization.
The right data architecture can help your organization improve data quality because it provides the framework that determines how data is collected, transported, stored, secured, used and shared for business intelligence and datascience use cases. Perform data quality monitoring based on pre-configured rules.
Datascience tasks such as machine learning also greatly benefit from good data integrity. When an underlying machine learning model is being trained on data records that are trustworthy and accurate, the better that model will be at making business predictions or automating tasks.
As discussed in the previous section data virtualization and data cataloging help get the right data to the right people by making it easier to find the data that best fits their needs and access it. Automated metadata generation is essential in order to turn a manual process into one that is better controlled.
Support data privacy, risk, and protection teams to “enrich the overall data taxonomy across the McDonald’s landscape,” Stephanie says — not just the normal asset model for business and technical metadata, but also risk metadata attributes to ensure compliance, brand protection and loyalty, and risk mitigation.
Vision One takes data from endpoints, servers, cloud, emails , and network security systems producing an XDR data lake of telemetry, metadata, logs, and netflow. Using datascience and ML, the Automated Defense software triages alerts, scales SOC capabilities , and accurate investigations 24/7.
This comprehensive solution comes without the excessive costs of switching from your current datascience platform. Automate the capture of model metadata and increase predictive accuracy to identify how AI is used and where models need to be reworked.
The Reltio MDM solution is part of the Connected Data Platform, which supports all data types in real time for operational, analytical, and datascience use cases.”. Using our APIs and user interface, you can create, publish, automate, and integrate various governance policies, such as: Data access.
What you can do more with Collibra data intelligence. Collibra Data Intelligence Cloud has a deep focus on intelligence about the data, as informed by metadata. Data intelligence enables people, processes, and technology to work with healthier data, power trusted insights, and drive better business outcomes.
But if your use case involves sentiment analysis and your data set is support tickets — and the customer information is NOT anonymized — then it’s probably not a viable use case. Usually, this step involves reaching out to relevant data owners. Maybe it’s your datascience colleague who has a store of transactional data.
Lastly, once the data governance framework is laid out, the committee will turn to technology and choose a platform that best supports the vision. A good technology solution will gather metadata from a variety of systems, manage a business glossary, enforce policies and procedures, tie to a technical data dictionary, and more.
Analytics using robotic process automation (RPA) can examine, analyze, and identify unstructured content and auto-classify data based on rules learned by the “AI engine.” When tagging and auto-classifying content, the AI engine can extract metadata to provide context to unstructured content.
On a business level, decisions based on bad external data may have the potential to cause business failures. In business, data is the food that feeds the body or enterprise. Better data makes the body stronger and provides a foundation for the use of analytics and datascience tools to reduce errors in decision-making.
The program also highlighted the emergence of datascience in the field: indeed, the conference started with a thought-provoking keynote called “ Truth is a Lie ,” in which data scientist Lora Aroyo and research scientist Chris Welty examined the concept of truth as not a single notion but a spectrum of opinions, perspectives, and context.
IBM’s Scaled DataScience Method , an extension of CRISP-DM, offers governance across the AI model lifecycle informed by collaborative input from data scientists, industrial-organizational psychologists, designers, communication specialists and others. This should all be baked into the interpretable, findable metadata).
We organize all of the trending information in your field so you don't have to. Join 55,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content